RAG(検索拡張生成)アプリケーション構築入門
RAGの基本概念からベクトルDBの選定、実装パターンまで、LLMアプリケーション開発に必要な知識を体系的に解説します。
RAGLLMベクトルDB

RAGとは何か
RAG(Retrieval-Augmented Generation)は、LLMの回答精度を向上させるアーキテクチャパターンです。外部の知識ベースから関連情報を検索し、それをLLMのコンテキストに含めることで、ハルシネーション(事実と異なる回答)を大幅に削減できます。
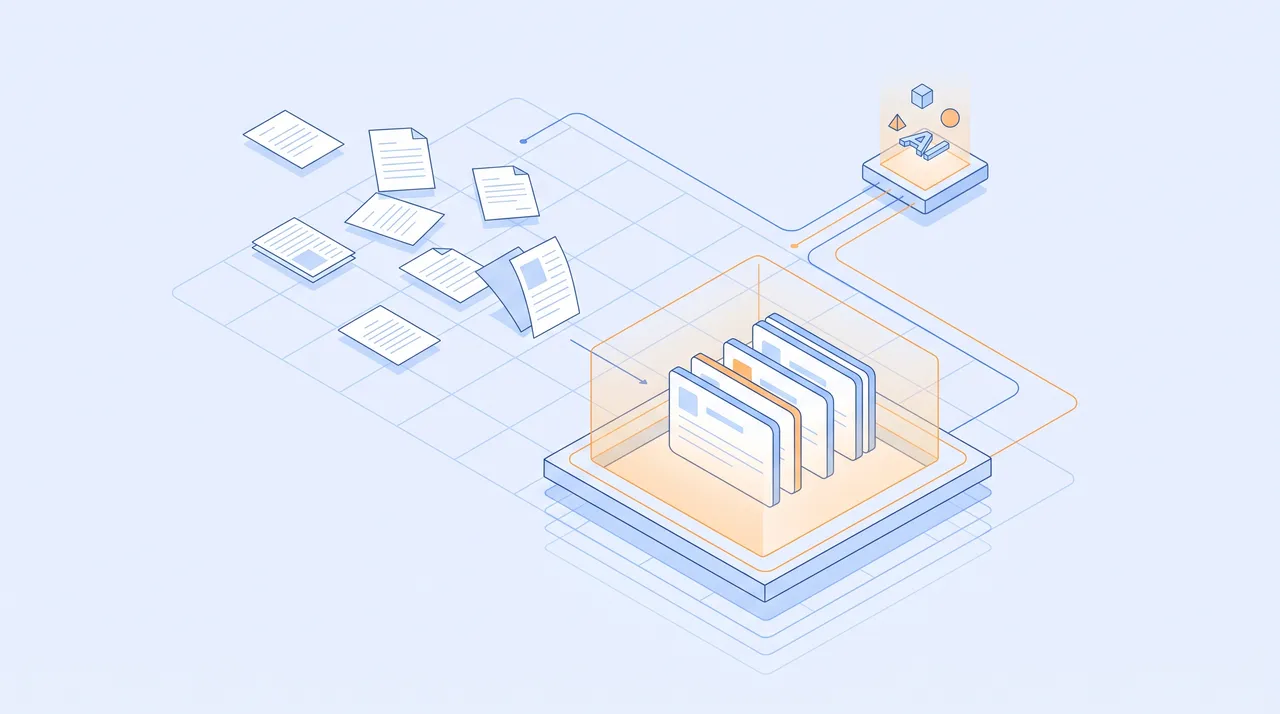
RAGの基本アーキテクチャ
RAGシステムは3つのコンポーネントで構成されます。
- インデクシング: ドキュメントをチャンクに分割し、Embeddingベクトルに変換してベクトルDBに格納
- 検索(Retrieval): ユーザーの質問をベクトル化し、類似度の高いチャンクを検索
- 生成(Generation): 検索結果をコンテキストとしてLLMに渡し、回答を生成
ユーザー質問
│
▼
[Embedding] → [ベクトルDB検索] → 関連チャンク取得
│
▼
[LLM + コンテキスト]
│
▼
回答生成チャンク分割の戦略
チャンクの分割方法はRAGの品質に直結します。当社の実績では、以下のアプローチが効果的でした。
- 固定長分割: 500〜1000トークン単位で分割(シンプルで安定)
- セマンティック分割: 段落や見出しの区切りで分割(文脈を保持)
- オーバーラップ: 前後100〜200トークンを重複させ、境界での情報欠落を防止
ベクトルDBの選定
主要なベクトルDBの特徴を整理します。
| DB | 特徴 | 適用場面 |
|---|---|---|
| Pinecone | フルマネージド、スケーラブル | 大規模本番環境 |
| Weaviate | オープンソース、ハイブリッド検索 | カスタマイズ重視 |
| pgvector | PostgreSQL拡張 | 既存RDBとの統合 |
精度向上のテクニック
RAGの回答精度を向上させるためには、検索精度の改善が鍵です。リランキング(検索結果の再順位付け)やHyDE(仮説的ドキュメント埋め込み)といった手法を組み合わせることで、検索精度を大幅に向上させることができます。
RAGは、企業の内部ナレッジを活用したAIアシスタント構築の基盤技術として、今後ますます重要になるでしょう。