中小企業でも実現できる!AWSサーバーレスETLパイプラインの設計と構築事例
DynamoDBの業務データをS3データレイクに集約し、Glue ETLで変換・分析する完全サーバーレスなデータ分析基盤の設計思想と構築アプローチを、実案件ベースで解説します。
中小企業でも実現できる!AWSサーバーレスETLパイプラインの設計と構築事例
① 課題の背景:「データはあるのに、活かせていない」
あるサービス業の企業様から、こんなご相談をいただきました。
「業務システムにはデータが溜まっているのに、前年比の売上分析をするだけでも担当者が手作業で半日かかっている。経営判断に使えるレポートをタイムリーに出せる仕組みがほしい。」
この課題は、中小企業のお客様から非常に多くいただくご相談のひとつです。業務システム(この案件ではDynamoDBベースのWebアプリケーション)にはデータが蓄積されているものの、分析のための「データの取り出し・加工・可視化」の仕組みがなく、Excelでの手作業に頼っているケースです。
そこで私たちは、AWSのサーバーレスサービスを組み合わせたETLパイプラインを設計・構築しました。本記事では、このプロジェクトで採用したアーキテクチャの設計思想と、技術選定の理由をご紹介します。
② アーキテクチャ設計:3層データレイク + サーバーレスETL
全体構成
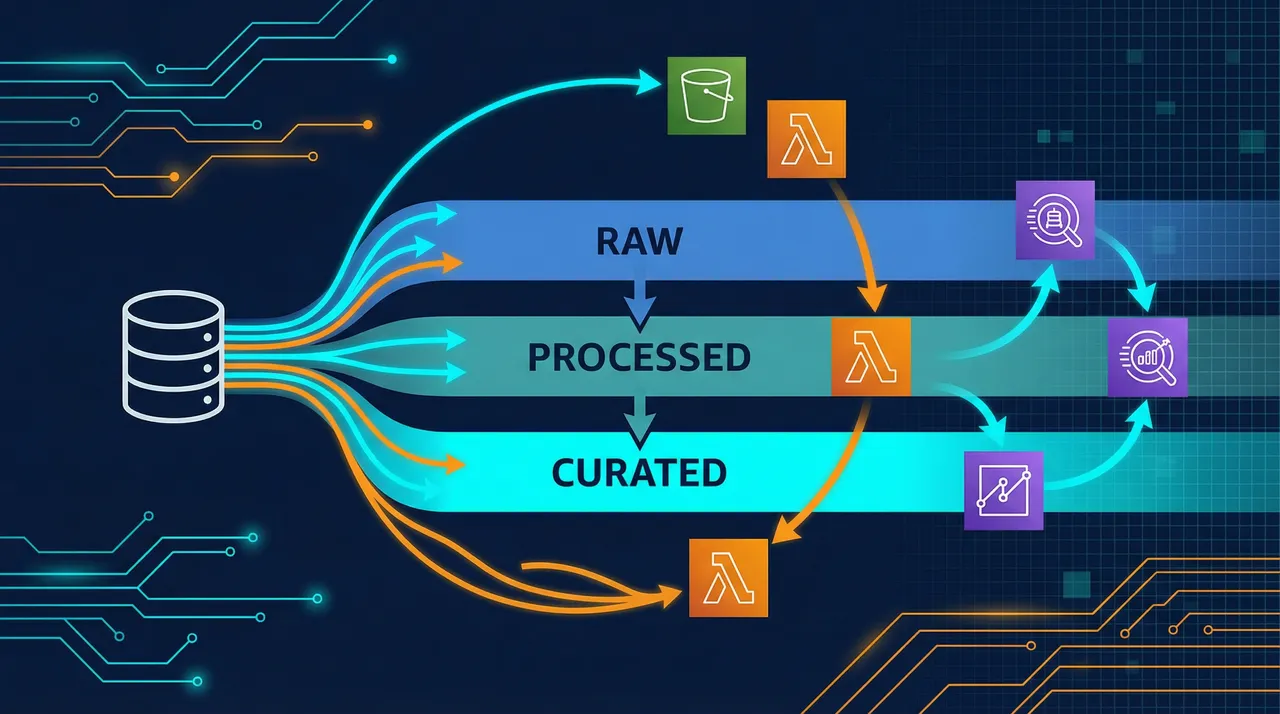
構築したパイプラインの全体像は以下のとおりです。
業務DB (DynamoDB)
│
▼ [Extract] AWS Glue ジョブ
│
S3 Data Lake
├── Raw層(JSON) ← 抽出したままの生データ
├── Processed層(Parquet) ← 型変換・クレンジング済み
└── Curated層(Parquet) ← ビジネスロジック適用済み
│
▼ [Query] Amazon Athena
│
BIツール(CSV Export)なぜ3層構造なのか
データレイクを Raw → Processed → Curated の3層に分けたのは、以下の理由です。
- Raw層: 業務DBからの抽出データをそのまま保存。障害時の再処理やデータ検証の起点になる
- Processed層: データ型の統一、NULL処理、フォーマット正規化を実施。Parquet形式に変換することでクエリ性能とストレージ効率を大幅に向上
- Curated層: 決算年度計算や集計区分の判定など、ビジネスロジックを適用した分析用データ。BIツールから直接参照可能
この3層設計により、「ビジネスロジックの変更があってもRaw層のデータから再処理できる」という運用上の安心感を確保しています。
技術選定のポイント
| コンポーネント | 採用技術 | 選定理由 |
|---|---|---|
| ETLジョブ | AWS Glue (PySpark) | サーバーレスでインフラ管理不要。ジョブブックマークで増分処理に対応 |
| データカタログ | AWS Glue Data Catalog | Athenaとシームレスに連携。スキーマ管理を一元化 |
| クエリエンジン | Amazon Athena | S3上のデータに直接SQLを発行可能。BI連携が容易 |
| オーケストレーション | AWS Step Functions | ジョブ間の依存関係・エラーハンドリングを宣言的に定義 |
| スケジューリング | Amazon EventBridge | 日次・月次の自動実行。タイムゾーン指定可能 |
| IaC | Terraform | 環境の再現性確保。ステージング→本番のプロモーション |
重要な判断として、すべてサーバーレスで構成しました。EC2やECSのようなサーバー管理が必要なサービスは一切使っていません。中小企業のお客様の場合、インフラ運用に割ける人員は限られています。「動いている間はコストが発生し、止まっていればゼロ」というサーバーレスの特性は、コスト面でもオペレーション面でも大きなメリットです。
③ 技術的なポイント:品質と運用を支える仕組み
データ品質チェックの組み込み
ETLジョブの中にデータ品質チェックを組み込みました。たとえば以下のような検証を自動で実行します。
- 必須フィールドのNULLチェック: 集計に必要なカラムが欠損していないか
- 数値の妥当性検証: 売上金額がマイナスになっていないか
- マルチテナント分離の確認: 異なるテナントのデータが混在していないか
これらのチェックはジョブの実行中にリアルタイムで行われ、異常があればCloudWatch Logsに記録されると同時にアラートが発火します。
オーケストレーションとエラーハンドリング
Step Functionsでジョブの実行順序を管理し、以下の信頼性設計を実装しています。
- 自動リトライ: 一時的な障害に対して最大2回のリトライ(指数バックオフ)
- タイムアウト制御: ジョブ単位・パイプライン全体のタイムアウトを設定
- X-Rayトレーシング: 実行時間のボトルネック特定に活用
監視ダッシュボード(9アラーム + 6ウィジェット)
CloudWatchで以下の監視体制を構築しました。
- ETLジョブ監視: 実行失敗、実行時間超過の検知
- パイプライン監視: Step Functions全体の失敗・タイムアウト検知
- エラーログ監視: ログストリームからのエラーパターン検知
- ダッシュボード: 日次実行状況、エラー率、処理時間の推移を可視化
SNS Topicを通じた通知により、異常があれば即座に担当者へアラートが届く体制です。
Terraformによる環境管理
インフラはすべてTerraformでコード化し、以下の構成で管理しています。
terraform/
├── staging/analytics/ # ステージング環境
│ ├── backend.tf # S3バックエンド
│ ├── locals.tf # 環境変数・プレフィックス
│ ├── s3.tf # データレイクバケット群
│ ├── iam.tf # 最小権限IAMロール
│ ├── glue_*.tf # ETLジョブ定義
│ ├── step_functions.tf # オーケストレーション
│ ├── eventbridge.tf # スケジューラー
│ └── cloudwatch.tf # 監視・アラート
└── production/analytics/ # 本番環境(同一構成)ステージングと本番で同一のTerraformモジュール構成を採用することで、「ステージングで動いたのに本番で動かない」というリスクを最小化しています。環境差分はlocals.tfの変数値のみです。
E2Eテストによる品質保証
本番デプロイ前に7フェーズの自動E2Eテストを実行しました。
- パイプライン全体の実行
- Raw層のデータ確認
- Curated層のデータ確認
- Athenaクエリ検証
- データ整合性チェック(前年比のNULL・異常値検知)
- マルチテナント分離確認
- CloudWatch監視の動作確認
この包括的なテストにより、データの正確性とインフラの信頼性を本番投入前に確認しています。
④ Papapapapa の見解:中小企業のデータ活用は「小さく始めて、確実に育てる」
このプロジェクトを通じて改めて実感したのは、中小企業のデータ分析基盤は 「最初から完璧を目指さない」 ことが成功の鍵だということです。
今回の案件では、まず1つの分析レポート(売上前年比)に絞ってパイプラインを構築し、本番稼働を確認してから他のレポートへ拡張する計画としました。最初から全データ・全レポートを対象にすると、要件定義だけで数ヶ月かかり、ROIが見えないまま予算が膨らむリスクがあります。
サーバーレスアーキテクチャは、この「小さく始める」アプローチと非常に相性がよいです。初期構築コストが低く、使った分だけの従量課金で、データ量やレポート数の増加に応じてスケールします。
もう一つ強調したいのは、Terraform(IaC)の重要性です。手作業でAWSコンソールから構築すると、ステージング環境と本番環境の差分が生まれやすく、「なぜか本番だけエラーになる」というトラブルの温床になります。Terraformでインフラをコード化しておけば、環境の複製・再構築が確実に行え、運用フェーズでの変更管理も容易です。
Papapapapa では、このようなデータ分析基盤の設計・構築を、お客様の業務理解から技術選定、構築、運用引き渡しまで一貫してサポートしています。「うちのデータ、もっと活かせるのでは?」とお感じの方は、ぜひお気軽にご相談ください。
⑤ まとめ
本記事では、実案件をベースに、AWSサーバーレスETLパイプラインの設計思想と構築アプローチを紹介しました。
- 3層データレイク設計(Raw/Processed/Curated)で再処理性と分析効率を両立
- 完全サーバーレス構成でインフラ運用コストを最小化
- Step Functions + EventBridgeでジョブオーケストレーションと自動スケジューリング
- CloudWatch 9アラーム + ダッシュボードで運用品質を確保
- Terraformで環境の再現性と変更管理を実現
- E2Eテストでデータ品質とインフラ信頼性を検証
中小企業であっても、適切な技術選定とアーキテクチャ設計を行えば、大企業に負けないデータ分析基盤を構築できます。「データはあるけど活かせていない」という課題をお持ちの方は、まず1つの分析テーマから始めてみませんか。
Papapapapa は、お客様の一歩目を全力でサポートします。
本記事は2026年3月時点の情報を元に作成しています。実案件の内容は匿名化・一般化して紹介しています。